CES 2018 in Las Vegas was all about Voice UI. It was the theme that ran through so many of the exhibitions and it dominated much of the social media posts and discussion on the fringe of the show.
We thought it would be a good idea to give you some insights into what it is all about.
Let’s go!
Designing Voice UI is currently trending at conferences around the world - but how do they work and can you design one for yourself or your own company?
Lets start with a quick explanation of the different components of Voice UI, then look at the design guidelines and development technologies you can use to create your own, and finally a little about the future of voice with a prediction about how it is going to see adoption in the coming years.
Voice UI is a series of distinct technologies that, when combined, allow people to interact with a machine using their voice. Those technologies all fall under the umbrella acronym NLP (Natural Language Processing) and include:
Automated speech recognition (ASR)
Accurately determining who is talking and whether their intent is to communicate with the voice UI.
Speech to text (STT)
Converting a recording of a voice from speech to a computer parsable format.
Semantic analysis
Figure out what a given voice interaction actually means using spoken words, context, sentiment and potentially other factors like environmental input from computer vision and the speaker’s history and social media profiles.
User Response
Respond to the user via text to speech (TTS), a screen or another suitable means of communication.
All of the major cloud service providers are adding Voice UI services via remote API calls to their online offerings.
| Made by | Product | Released | Languages |
|---|---|---|---|
| Apple | Siri | Oct 2011 | 20+ |
| Amazon | Alexa | Nov 2014 | English, German |
| Microsoft | Cortana | Dec 2015 | English, Portuguese, French, German, Italian, Spanish, Chinese, and Japanese |
| Assistant | Feb 2017 | English, French, German, Hindi, Indonesian, Japanese, Portuguese, and Spanish | |
| Home | May 2017 | English |
Startups like VIV.ai and Wit.ai have already been bought up by Samsung and Facebook respectively, while others, like Voysis are offering independent competing services to the major cloud providers.
Unless you want to start from scratch, using one of the third party service providers that offer access to their AI services is the approach to take. You can check out the developer entry points here:
Voice UI’s come in one of two forms - always on devices like Alexa that passively listens at all times and on demand AI assistants that activate with the click of a button like Siri or Google.
Always on connections are more responsive and don’t require a user to take any action other than to speak - however they tend to use a lot more power making them unsuitable for mobile devices.
The first step in understanding how to design voice UI experiences is to understand what a good voice UI experience can be like.
Thankfully, many of the main providers provide guidelines for working on their platforms:
There are also plenty of other great articles out there to get familiar with designing for Voice:
While there is some suggestion that voice UI is now mainstream, user engagement with voice apps still trails other mediums like touch. Voice UI is likely not good enough to replace mouse / touch, but it can function as an additional input mechanism for users in controlled situations.
The two biggest problems are accuracy and connectivity.
New technologies must make tasks faster and easier in order to be viable replacements for existing tools. For short tasks, voice-detection errors can make this impossible. (NNGroup)
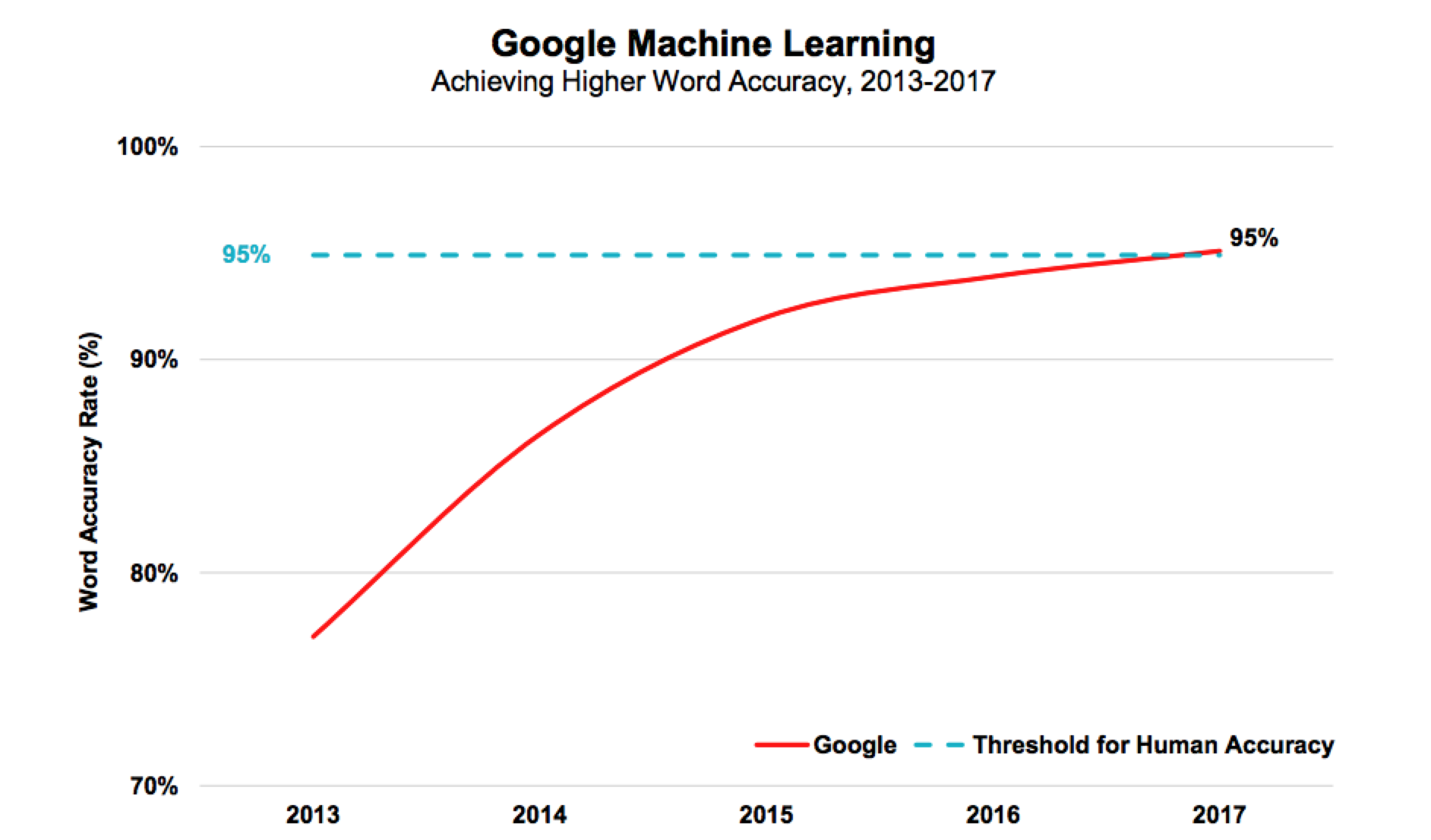
Accuracy is often the first metric touted when talking about progress in interpreting human speech.
There have been significant improvements in the last 7 years, but as of yet, none of the commercial solutions on the market (Oct 2017) are even close to anything other than “good” and even then, only in highly controlled environments.
99 percent is the key metric: As accuracy in low-noise environments rises from 95 to 99 percent, voice recognition technology will expand from limited usage to massive adoption. - Andrew Ng, Stanford professor current chief scientist at Baidu
While accuracy rates have improved significantly over the last few years, improvement levels have slowed, indicating new technologies are needed rather than iterative improvements to existing ones.
No one wants to wait 10 seconds for a response. Accuracy, followed by latency, are the two key metrics for a production speech system (Andrew Ng, Chief Scientist, Baidu).
End to end Voice UI technology is still in its infancy in 2017.
The study of natural language processing started around the same time the first nuclear hydrogen bombs were being tested, but has sadly lagged behind its more destructive brother in terms of achieving its ultimate goal.
Voice UI is a tough nut to crack. just like we learned over 60 years ago:

A lot of exciting things are happening and the applications for Voice UI tech are many. But interactive conversations are still a long way away. It will happen, but continuous improvements to existing products through AI is far more likely to see success in the near futures.